Very Long Instruction Word (VLIW) processing
Implemented in Explicit Parallel Instruction Computing (EPIC)
Motivation #
In Superscalar Processors , hardware has to actively search for independent insturctions for Out-Of-Order Execution . This has high hardware overhead and significant power consumption. the means to find independent instructions are also limited, since the search space is limited only issue queue (see Issue Stage ) can be searched.
Solution #
Compiler is responsible for determining which parts can run in parrallel and thus are independent, hardware does not have to look for it. Compilers have a more global view of the program anyways. This needs a different ISA .
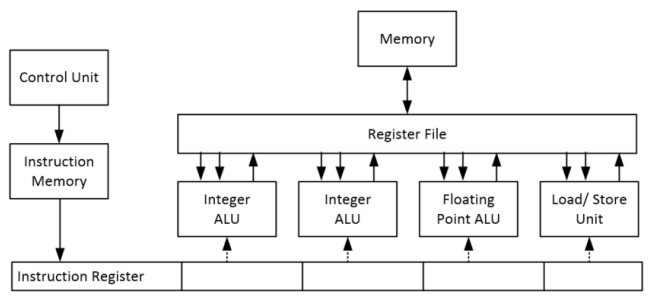
One “Instruction” in a VLIW Architecture contains one instruction for each
functional unit defined in the ISA
, can also be nop for some FUs.
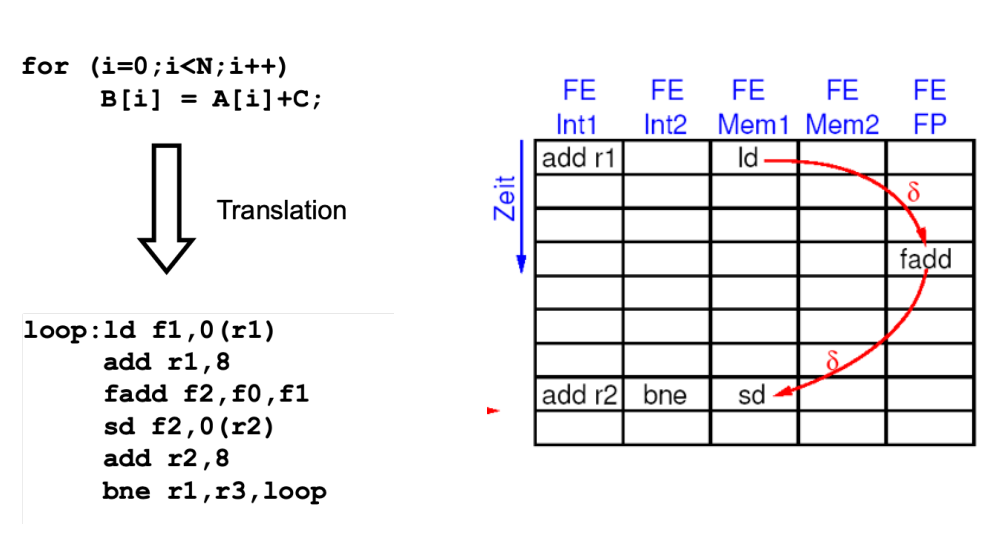
Compiler code generation for VLIW #
Trivial translation #
Loop unrolled #

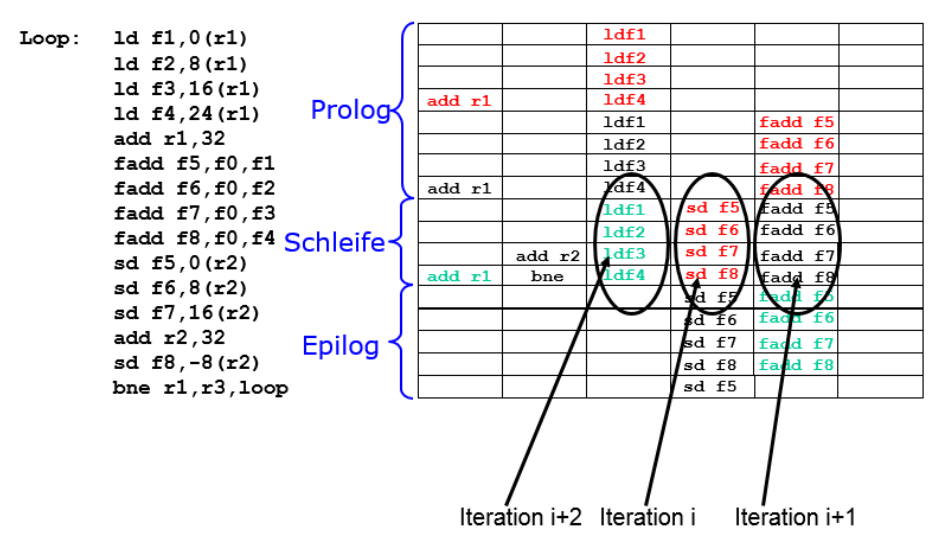
With Software pipelining #
Advantages #
- No renaming since parallelism is explicit
- Hazard detection between VLIW instructions is still required
Disadvantages #
- ISA has to define the functional units
- Latencies of functional units are visible
- static in-order scheduling
nopsin VLIW instruction lead to significant memory overhead