DeepSDF
- DeepSDF is an auto-decoder based approach that learns a continuous SDF
representation for a class of shapes. Once trained, it can be used for
- shape representation
- interpolation
- shape completion
Bibtex #
@inproceedings{park2019deepsdf,
title={Deepsdf: Learning continuous signed distance functions for shape
representation},
author={Park, Jeong Joon and Florence, Peter and Straub, Julian and Newcombe,
Richard and Lovegrove, Steven},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition},
pages={165--174},
year={2019}
}
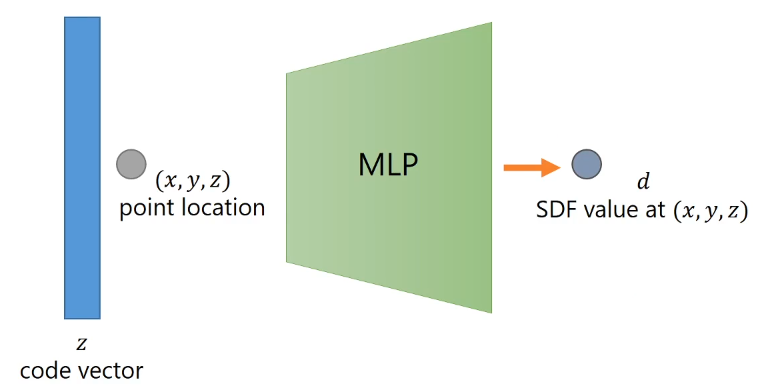
Overview #
- Not tied to a grid structure
- During training, the autodecoder optimizes both the network parameters and the latent codes representing each of the training shapes. Once trained, to reconstruct a shape given its SDF observations, a latent code is optimized keeping the network parameters fixed, such that the optimized latent code gives the lowest error with observed SDF values.
Architecture #
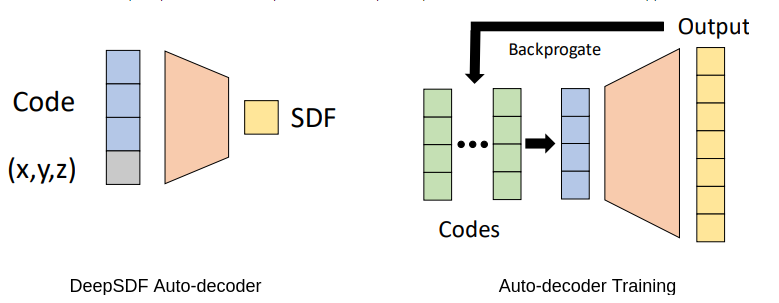
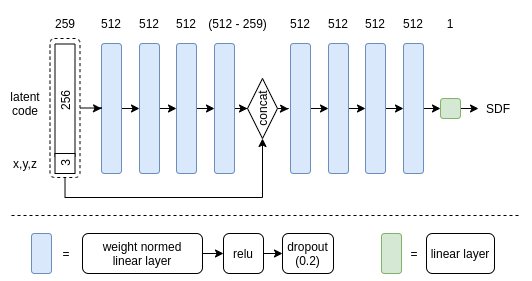
Figure 1: Architecture of the Auto-decoder
Implementation #
Model #
import torch.nn as nn
import torch
class DeepSDFDecoder(nn.Module):
def __init__(self, latent_size):
"""
:param latent_size: latent code vector length
"""
super().__init__()
dropout_prob = 0.2
# NOTE: Define model
self.lin0 = nn.utils.weight_norm(nn.Linear(259, 512))
self.lin1 = nn.utils.weight_norm(nn.Linear(512, 512))
self.lin2 = nn.utils.weight_norm(nn.Linear(512, 512))
self.lin3 = nn.utils.weight_norm(nn.Linear(512, (512 - 259)))
self.lin4 = nn.utils.weight_norm(nn.Linear(512, 512))
self.lin5 = nn.utils.weight_norm(nn.Linear(512, 512))
self.lin6 = nn.utils.weight_norm(nn.Linear(512, 512))
self.lin7 = nn.utils.weight_norm(nn.Linear(512, 512))
self.lin8 = nn.Linear(512, 1)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout_prob)
def forward(self, x_in):
"""
:param x_in: B x (latent_size + 3) tensor
:return: B x 1 tensor
"""
# NOTE: implement forward pass
x = self.lin0(x_in)
x = self.relu(x)
x = self.dropout(x)
x = self.lin1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.lin2(x)
x = self.relu(x)
x = self.dropout(x)
x = self.lin3(x)
x = self.relu(x)
x = self.dropout(x)
x = torch.cat((x, x_in), dim=1)
x = self.lin4(x)
x = self.relu(x)
x = self.dropout(x)
x = self.lin5(x)
x = self.relu(x)
x = self.dropout(x)
x = self.lin6(x)
x = self.relu(x)
x = self.dropout(x)
x = self.lin7(x)
x = self.relu(x)
x = self.dropout(x)
x = self.lin8(x)
return x
Inference #
import random
from pathlib import Path
import torch
import numpy as np
from exercise_3.data.shape_implicit import ShapeImplicit
from exercise_3.model.deepsdf import DeepSDFDecoder
from exercise_3.util.misc import evaluate_model_on_grid
class InferenceHandlerDeepSDF:
def __init__(self, latent_code_length, experiment, device):
"""
:param latent_code_length: latent code length for the trained DeepSDF model
:param experiment: path to experiment folder for the trained model; should contain "model_best.ckpt" and "latent_best.ckpt"
:param device: torch device where inference is run
"""
self.latent_code_length = latent_code_length
self.experiment = Path(experiment)
self.device = device
self.truncation_distance = 0.01
self.num_samples = 4096
def get_model(self):
"""
:return: trained deep sdf model loaded from disk
"""
model = DeepSDFDecoder(self.latent_code_length)
model.load_state_dict(torch.load(self.experiment / "model_best.ckpt", map_location='cpu'))
model.eval()
model.to(self.device)
return model
def get_latent_codes(self):
"""
:return: latent codes which were optimized during training
"""
latent_codes = torch.nn.Embedding.from_pretrained(torch.load(self.experiment / "latent_best.ckpt", map_location='cpu')['weight'])
latent_codes.to(self.device)
return latent_codes
def reconstruct(self, points, sdf, num_optimization_iters):
"""
Reconstructs by optimizing a latent code that best represents the input sdf observations
:param points: all observed points for the shape which needs to be reconstructed
:param sdf: all observed sdf values corresponding to the points
:param num_optimization_iters: optimization is performed for this many number of iterations
:return: tuple with mesh representations of the reconstruction
"""
model = self.get_model()
# NOTE: define loss criterion for optimization
loss_l1 = torch.nn.L1Loss()
# initialize the latent vector that will be optimized
latent = torch.ones(1, self.latent_code_length).normal_(mean=0, std=0.01).to(self.device)
latent.requires_grad = True
# NOTE: create optimizer on latent, use a learning rate of 0.005
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
for iter_idx in range(num_optimization_iters):
# NOTE: zero out gradients
optimizer.zero_grad()
# NOTE: sample a random batch from the observations, batch size =
# self.num_samples
batch_indices = np.random.choice(points.shape[0], self.num_samples)
batch_points = points[batch_indices, :]
batch_sdf = sdf[batch_indices, :]
# move batch to device
batch_points = batch_points.to(self.device)
batch_sdf = batch_sdf.to(self.device)
# same latent code is used per point, therefore expand it to have same length as batch points
latent_codes = latent.expand(self.num_samples, -1)
# NOTE: forward pass with latent_codes and batch_points
nn_input = torch.cat((latent_codes, batch_points), dim=1)
predicted_sdf = model(nn_input)
# NOTE: truncate predicted sdf between -0.1, 0.1
predicted_sdf = torch.clip(predicted_sdf, -0.1, 0.1)
# compute loss wrt to observed sdf
loss = loss_l1(predicted_sdf, batch_sdf)
# regularize latent code
loss += 1e-4 * torch.mean(latent.pow(2))
# NOTE: backwards and step
loss.backward()
optimizer.step()
# loss logging
if iter_idx % 50 == 0:
print(f'[{iter_idx:05d}] optim_loss: {loss.cpu().item():.6f}')
print('Optimization complete.')
# visualize the reconstructed shape
vertices, faces = evaluate_model_on_grid(model, latent.squeeze(0), self.device, 64, None)
return vertices, faces
def interpolate(self, shape_0_id, shape_1_id, num_interpolation_steps):
"""
Interpolates latent codes between provided shapes and exports the intermediate reconstructions
:param shape_0_id: first shape identifier
:param shape_1_id: second shape identifier
:param num_interpolation_steps: number of intermediate interpolated points
:return: None, saves the interpolated shapes to disk
"""
# get saved model and latent codes
model = self.get_model()
train_latent_codes = self.get_latent_codes()
# get indices of shape_ids latent codes
train_items = ShapeImplicit(4096, "train").items
latent_code_indices = torch.LongTensor([train_items.index(shape_0_id), train_items.index(shape_1_id)]).to(self.device)
# get latent codes for provided shape ids
latent_codes = train_latent_codes(latent_code_indices)
for i in range(0, num_interpolation_steps + 1):
# NOTE: interpolate the latent codes: latent_codes[0, :] and latent_codes[1, :]
t = i / num_interpolation_steps
interpolated_code = (1-t) * latent_codes[0, :] + t * latent_codes[1, :]
# reconstruct the shape at the interpolated latent code
evaluate_model_on_grid(model, interpolated_code, self.device, 64, self.experiment / "interpolation" / f"{i:05d}_000.obj")
def infer_from_latent_code(self, latent_code_index):
"""
Reconstruct shape from a given latent code index
:param latent_code_index: shape index for a shape in the train set for which reconstruction is performed
:return: tuple with mesh representations of the reconstruction
"""
# get saved model and latent codes
model = self.get_model()
train_latent_codes = self.get_latent_codes()
# get latent code at given index
latent_code_indices = torch.LongTensor([latent_code_index]).to(self.device)
latent_codes = train_latent_codes(latent_code_indices)
# reconstruct the shape at latent code
vertices, faces = evaluate_model_on_grid(model, latent_codes[0], self.device, 64, None)
return vertices, faces
Training #
from pathlib import Path
import torch
from exercise_3.model.deepsdf import DeepSDFDecoder
from exercise_3.data.shape_implicit import ShapeImplicit
from exercise_3.util.misc import evaluate_model_on_grid
def train(model, latent_vectors, train_dataloader, device, config):
# Declare loss and move to device
# NOTE: declare loss as `loss_criterion`
loss_criterion = torch.nn.L1Loss()
loss_criterion.to(device)
# declare optimizer
optimizer = torch.optim.Adam([
{
# NOTE: optimizer params and learning rate for model (lr provided in config)
"params" : model.parameters(),
"lr" : config["learning_rate_model"],
},
{
# NOTE: optimizer params and learning rate for latent code (lr provided in config)
"params": latent_vectors.parameters(),
"lr" : config["learning_rate_code"],
}
])
# declare learning rate scheduler
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=500, gamma=0.5)
# Set model to train
model.train()
# Keep track of running average of train loss for printing
train_loss_running = 0.
# Keep track of best training loss for saving the model
best_loss = float('inf')
for epoch in range(config['max_epochs']):
for batch_idx, batch in enumerate(train_dataloader):
# Move batch to device
ShapeImplicit.move_batch_to_device(batch, device)
# NOTE: Zero out previously accumulated gradients
optimizer.zero_grad()
# calculate number of samples per batch (= number of shapes in batch * number of points per shape)
num_points_per_batch = batch['points'].shape[0] * batch['points'].shape[1]
# get latent codes corresponding to batch shapes
# expand so that we have an appropriate latent vector per sdf sample
batch_latent_vectors = latent_vectors(batch['indices']).unsqueeze(1).expand(-1, batch['points'].shape[1], -1)
batch_latent_vectors = batch_latent_vectors.reshape((num_points_per_batch, config['latent_code_length']))
# reshape points and sdf for forward pass
points = batch['points'].reshape((num_points_per_batch, 3))
sdf = batch['sdf'].reshape((num_points_per_batch, 1))
# NOTE: perform forward pass
nn_input = torch.cat((batch_latent_vectors, points), dim=1)
predicted_sdf = model(nn_input)
# NOTE: truncate predicted sdf between -0.1 and 0.1
predicted_sdf = torch.clip(predicted_sdf, -0.1, 0.1)
# compute loss
loss = loss_criterion(predicted_sdf, sdf)
# regularize latent codes
code_regularization = torch.mean(torch.norm(batch_latent_vectors, dim=1)) * config['lambda_code_regularization']
if epoch > 100:
loss = loss + code_regularization
# NOTE: backward
loss.backward()
# NOTE: update network parameters
optimizer.step()
# loss logging
train_loss_running += loss.item()
iteration = epoch * len(train_dataloader) + batch_idx
if iteration % config['print_every_n'] == (config['print_every_n'] - 1):
train_loss = train_loss_running / config["print_every_n"]
print(f'[{epoch:03d}/{batch_idx:05d}] train_loss: {train_loss:.6f}')
# save best train model and latent codes
if train_loss < best_loss:
torch.save(model.state_dict(), f'exercise_3/runs/{config["experiment_name"]}/model_best.ckpt')
torch.save(latent_vectors.state_dict(), f'exercise_3/runs/{config["experiment_name"]}/latent_best.ckpt')
best_loss = train_loss
train_loss_running = 0.
# visualize first 5 training shape reconstructions from latent codes
if iteration % config['visualize_every_n'] == (config['visualize_every_n'] - 1):
# Set model to eval
model.eval()
latent_vectors_for_vis = latent_vectors(torch.LongTensor(range(min(5, latent_vectors.num_embeddings))).to(device))
for latent_idx in range(latent_vectors_for_vis.shape[0]):
# create mesh and save to disk
evaluate_model_on_grid(model, latent_vectors_for_vis[latent_idx, :], device, 64, f'exercise_3/runs/{config["experiment_name"]}/meshes/{iteration:05d}_{latent_idx:03d}.obj')
# set model back to train
model.train()
# lr scheduler update
scheduler.step()
def main(config):
"""
Function for training DeepSDF
:param config: configuration for training - has the following keys
'experiment_name': name of the experiment, checkpoint will be saved to folder "exercise_2/runs/<experiment_name>"
'device': device on which model is trained, e.g. 'cpu' or 'cuda:0'
'num_sample_points': number of sdf samples per shape while training
'latent_code_length': length of deepsdf latent vector
'batch_size': batch size for training and validation dataloaders
'resume_ckpt': None if training from scratch, otherwise path to checkpoint (saved weights)
'learning_rate_model': learning rate of model optimizer
'learning_rate_code': learning rate of latent code optimizer
'lambda_code_regularization': latent code regularization loss coefficient
'max_epochs': total number of epochs after which training should stop
'print_every_n': print train loss every n iterations
'visualize_every_n': visualize some training shapes every n iterations
'is_overfit': if the training is done on a small subset of data specified in exercise_2/split/overfit.txt,
train and validation done on the same set, so error close to 0 means a good overfit. Useful for debugging.
"""
# declare device
device = torch.device('cpu')
if torch.cuda.is_available() and config['device'].startswith('cuda'):
device = torch.device(config['device'])
print('Using device:', config['device'])
else:
print('Using CPU')
# create dataloaders
train_dataset = ShapeImplicit(config['num_sample_points'], 'train' if not config['is_overfit'] else 'overfit')
train_dataloader = torch.utils.data.DataLoader(
train_dataset, # Datasets return data one sample at a time; Dataloaders use them and aggregate samples into batches
batch_size=config['batch_size'], # The size of batches is defined here
shuffle=True, # Shuffling the order of samples is useful during training to prevent that the network learns to depend on the order of the input data
num_workers=0, # Data is usually loaded in parallel by num_workers
pin_memory=True # This is an implementation detail to speed up data uploading to the GPU
)
# Instantiate model
model = DeepSDFDecoder(config['latent_code_length'])
# Instantiate latent vectors for each training shape
latent_vectors = torch.nn.Embedding(len(train_dataset), config['latent_code_length'], max_norm=1.0)
# Load model if resuming from checkpoint
if config['resume_ckpt'] is not None:
model.load_state_dict(torch.load(config['resume_ckpt'] + "_model.ckpt", map_location='cpu'))
latent_vectors = torch.nn.Embedding.from_pretrained(torch.load(config['resume_ckpt'] + "_latent.ckpt", map_location='cpu'))
# Move model to specified device
model.to(device)
latent_vectors.to(device)
# Create folder for saving checkpoints
Path(f'exercise_3/runs/{config["experiment_name"]}').mkdir(exist_ok=True, parents=True)
# Start training
train(model, latent_vectors, train_dataloader, device, config)