import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
class TNet(nn.Module):
def __init__(self, k):
super().__init__()
# NOTE Add layers: Convolutional k->64, 64->128, 128->1024 with
# corresponding batch norms and ReLU
self.conv1 = nn.Conv1d(in_channels=k, out_channels=64, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=1)
self.conv3 = nn.Conv1d(in_channels=128, out_channels=1024, kernel_size=1)
# NOTE Add layers: Linear 1024->512, 512->256, 256->k^2 with
# corresponding batch norms and ReLU
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
self.fc1 = torch.nn.Linear(1024, 512)
self.fc2 = torch.nn.Linear(512, 256)
self.fc3 = torch.nn.Linear(256, k**2)
self.register_buffer('identity', torch.from_numpy(np.eye(k).flatten().astype(np.float32)).view(1, k ** 2))
self.k = k
def forward(self, x):
b = x.shape[0]
# NOTE Pass input through layers, applying the same max operation as in
# PointNetEncoder
layers = [
self.conv1,
self.bn1,
self.relu,
self.conv2,
self.bn2,
self.relu,
self.conv3,
self.bn3,
self.relu,
# NOTE maxpooling
lambda x: torch.max(x, 2, keepdim=True)[0],
lambda x: x.view(-1, 1024),
self.fc1,
self.bn4,
self.relu,
self.fc2,
self.bn5,
self.relu,
self.fc3,
]
for layer in layers:
x = layer(x)
# NOTE No batch norm and relu after the last Linear layer
# Adding the identity to constrain the feature transformation matrix to
# be close to orthogonal matrix
identity = self.identity.repeat(b, 1)
x = x + identity
x = x.view(-1, self.k, self.k)
return x
class PointNetEncoder(nn.Module):
def __init__(self, return_point_features=False):
super().__init__()
# TODO Define convolution layers, batch norm layers, and ReLU
self.conv1 = nn.Conv1d(in_channels=3, out_channels=64, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=1)
self.conv3 = nn.Conv1d(in_channels=128, out_channels=1024, kernel_size=1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.relu = nn.ReLU()
self.input_transform_net = TNet(k=3)
self.feature_transform_net = TNet(k=64)
self.return_point_features = return_point_features
def forward(self, x):
num_points = x.shape[2]
input_transform = self.input_transform_net(x)
x = torch.bmm(x.transpose(2, 1), input_transform).transpose(2, 1)
# NOTE: First layer: 3->64
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
feature_transform = self.feature_transform_net(x)
x = torch.bmm(x.transpose(2, 1), feature_transform).transpose(2, 1)
point_features = x
# NOTE: Layers 2 and 3: 64->128, 128->1024
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
# This is the symmetric max operation
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
if self.return_point_features:
x = x.view(-1, 1024, 1).repeat(1, 1, num_points)
return torch.cat([x, point_features], dim=1)
else:
return x
class PointNetClassification(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.encoder = PointNetEncoder(return_point_features=False)
# NOTE Add Linear layers, batch norms, dropout with p=0.3, and ReLU.
#
# Batch Norms and ReLUs are used after all but the last layer Dropout
# is used only directly after the second Linear layer. The last Linear
# layer reduces the number of feature channels to num_classes (=k in
# the architecture visualization)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, num_classes)
self.dropout = nn.Dropout(0.3)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
def forward(self, x):
x = self.encoder(x)
# NOTE Pass output of encoder through your layers
x = self.fc1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.bn2(x)
x = self.relu(x)
x = self.fc3(x)
return x
class PointNetSegmentation(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
self.encoder = PointNetEncoder(return_point_features=True)
# NOTE: Define convolutions, batch norms, and ReLU
self.conv1 = nn.Conv1d(in_channels=1088, out_channels=512, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=512, out_channels=256, kernel_size=1)
self.conv3 = nn.Conv1d(in_channels=256, out_channels=128, kernel_size=1)
self.conv4 = nn.Conv1d(in_channels=128, out_channels=num_classes, kernel_size=1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
self.relu = nn.ReLU()
def forward(self, x):
x = self.encoder(x)
# NOTE: Pass x through all layers, no batch norm or ReLU after the last conv layer
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
x = x.transpose(2, 1).contiguous()
return x
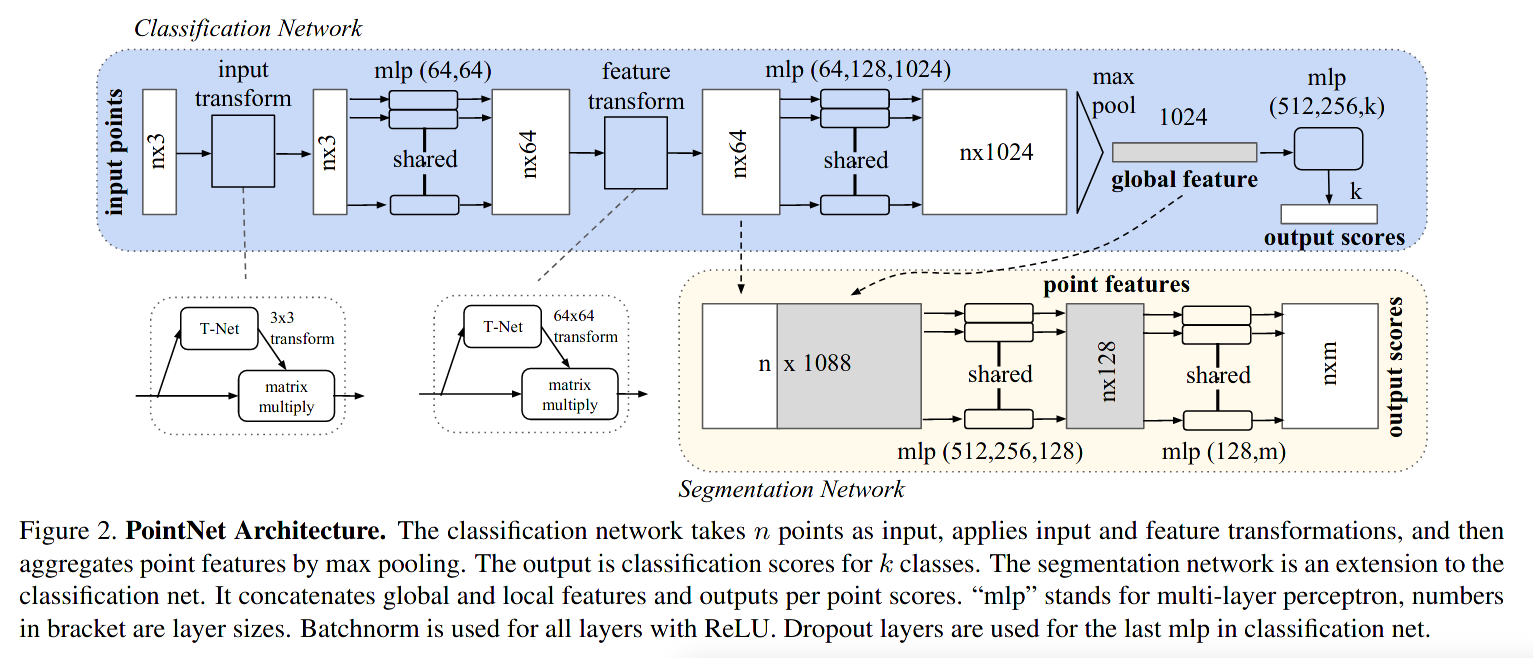
 affine transform matrix that is
applied to all points to align them
affine transform matrix that is
applied to all points to align them and multiply with feature vectors
and multiply with feature vectors segmentation
classes for each point
segmentation
classes for each point