Semantic Scene Segmentation
- ScanNet (indoors)
- Benchmark to compare segmentation approaches
- KITTI (outdoors)
- Benchmark for ourdoors, for autonomous cars and such
- Scene segmentation is related to 3D Shape Segmentation but scales are really different.
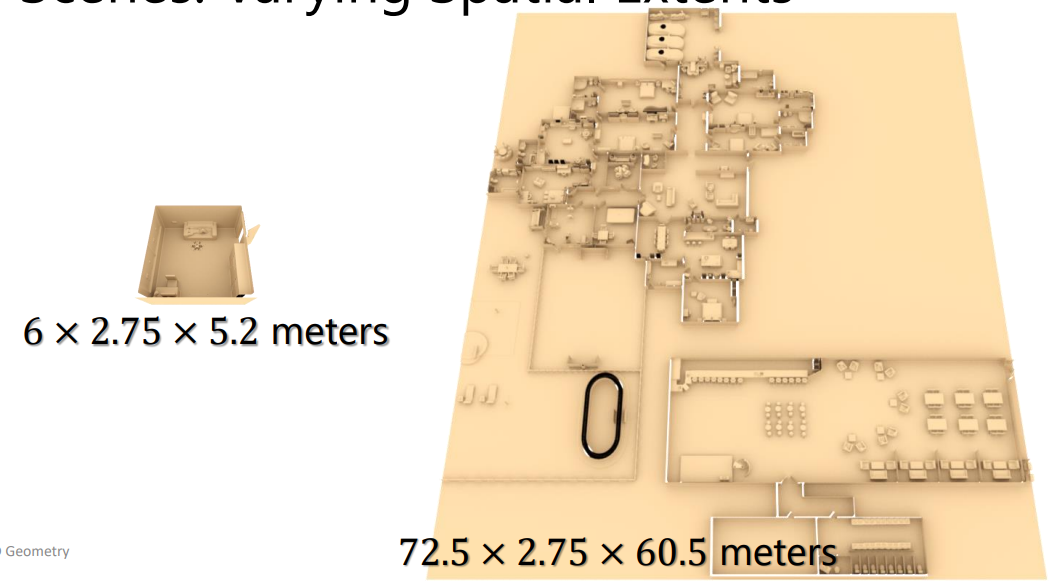
Dealing with varying spatial extends #
- With Images
- rescaling the image to a lower resolution is mostly fine, this is done such that the NN has a foxed size input
- In 3D
- when scaling down shapes, then the scale information is lost; Cars will have the same size as chairs, etc
- Also for scenes
- Objects of same size in different scenes will be precieved differently when scenes are rescaled to a fixed size
Approaches #
| ScanNet | Scan -> semantic segmentation |
|---|---|
| 3DMV | Joint Multi-View RGBD images + scans -> semantic segmentation |
| ScanComplete | Incomplete scan -> only convs -> semantic segmentation |
| TextureNet | Textured mesh -> semantic segmentation |
| KPConv | Convolution on points -> semantic segmentation |
| OccuSeg | -> instance segmentation |
| Virtual MVFusion | -> semantic segmentation |