Virtual Multi-view Fusion for 3D Semantic Segmentation
@inproceedings{kundu2020virtual,
title={Virtual multi-view fusion for 3d semantic segmentation},
author={Kundu, Abhijit and Yin, Xiaoqi and Fathi, Alireza and Ross, David and
Brewington, Brian and Funkhouser, Thomas and Pantofaru, Caroline},
booktitle={European Conference on Computer Vision},
pages={518--535},
year={2020},
organization={Springer}
}
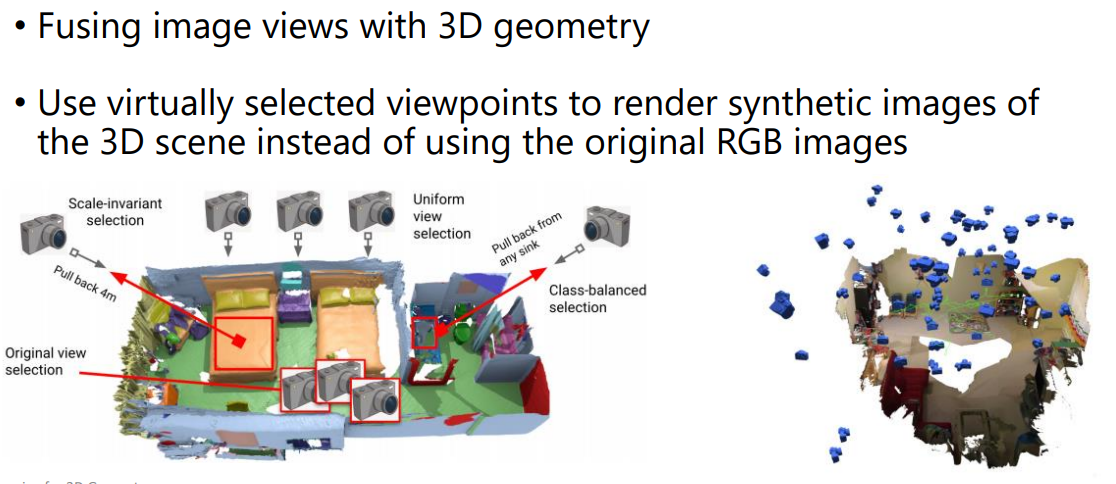
-
Not limited to real/possible camera angles
-
Use pre-trained 2D semantic segmentation
-
Back-project all 2D features to 3D
-
Aggregate all projected 2D features for a 3D point by average
-
No explicit 3D convolutions
Given a 3D mesh reconstructed from RGBD sensors, our method effectively chooses different virtual views of the 3D mesh and renders multiple 2D channels for training an effective 2D semantic segmentation model. Features from multiple per view predictions are finally fused on 3D mesh vertices to predict mesh semantic segmentation labels